یکی از چالشهای بزرگ در علم اطلاعات، انجام محاسبات بدون خطا در حالت ایدهآل و انجام محاسبات با خطای معقول در واقعیت است، و این در حالی است که شکسته شدن یا از بین رفتن اطلاعات بیت موجب ایجاد خطا میشود. خطا هم در رایانش کلاسیک و هم در رایانش کوانتومی رخ میدهد. در روش کلاسیک برای اجتناب و رفع خطا، از دادهها کپیبرداری میشود ولی در کوانتوم این کار عملی نیست. از طرفی پردازندههای حاضر نرخ خطای بالایی در اجرای هر دروازه از خود نشان میدهند و اینجاست که ضرورت دستیابی به یک روش و پروتکل تصحیح خطای بهینه احساس میشود.
تصحیح خطای کوانتومی نیاز به اجرا در آنسامبلی از کیوبیتها دارد و لذا باید تعداد کیوبیتها افزایش یابد. در روشی نوین، برای اجتناب از افزایش خطا حاصل از افزایش کیوبیت، کدبندی بیتها به گونهای است که آنسامبلی از آنها به صورت یک کیوبیت منطقی عمل کنند. روشهای مختلفی برای تصحیح خطا تا به حال ارائه شدهاند. در تئوری، بین تصحیح فیزیکی خطا و کاهش خطای منطقی رابطهی مستقیمی وجود دارد و از طرفی رابطهی معکوسی بین خطای منطقی پایین و مقیاس دستگاه برای رسیدن به قابلیت اجرای کد تصحیح خطا برقرار است.
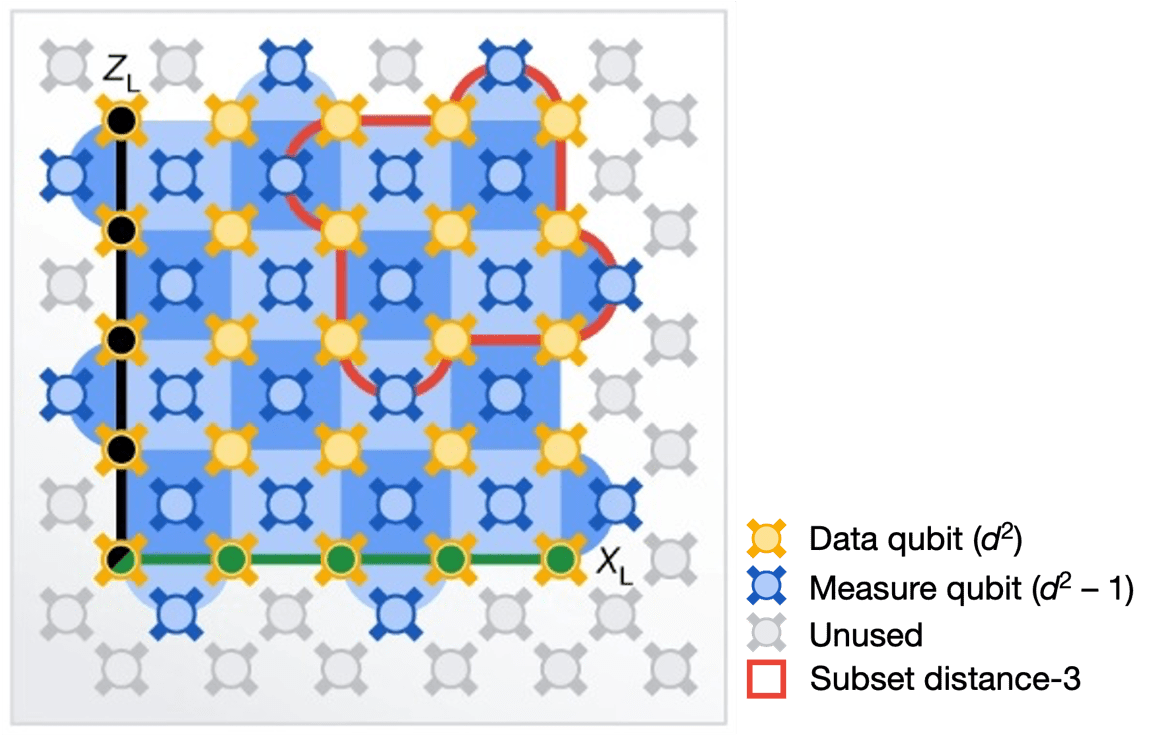
شکل ۱: مدلی از عملکرد دستگاه سیکامور ۷۲ کیوبیتی
یکی از این روشها استفاده از کد سطحی است که در آن کدبندی بیتهای اطلاعات در آرایهای از کیوبیتها انجام میشود. برای محافظت در برابر خطاهای کوانتومی، کدهای سطحی از مجموعهای از کدهای تصحیح خطای کوانتومی استفاده میکنند که از طریق درهمتنیدگی، یک کیوبیت را به یک کیوبیت منطقی تبدیل میکند که از خوشهای از کیوبیتهای فیزیکی d × d (که کیوبیتهای داده نیز نامیده میشود) تشکیل شده است. تعریف حالتهای کیوبیت منطقی بر اساس دو مشاهدهپذیر منطقی ZL و XL صورت میگیرد که نسبت به هم پادجابجاپذیر هستند. برای نشان دادن ایدهی ارائه شده، استفاده از پاریتهی مبتنی بر Z مشترک از بالا به پایین بر روی خط عمودی شبکهی کیوبیتها، یکی از راههای کدبندی یک مشاهدهپذیر ZL است. به طور مشابه، یک مشاهدهپذیر XL را میتوان با پاریتهی مبتنی بر X مشترک که از چپ به راست بر روی خط افقی کیوبیتهای شبکه اجرا میشود، کدبندی کرد (شکل 1). تا زمانی که خطاها قابل شناسایی و اصلاح باشند، کیوبیت منطقی در برابر خطاهای فیزیکی در سطح موضعی با استفاده از رمزگذاری غیر موضعی اطلاعات، کاملاً محفاظت میشوند.
شکل ۱ مدلی از عملکرد دستگاه سیکامور 72 کیوبیتی را نشان میدهد که دارای کد سطحی با فاصلهی 5 است. کد سطحی شامل 25 کیوبیت داده به رنگ طلایی و 24 کیوبیت اندازه به رنگ آبی است. هر کیوبیت مورد استفاده در فرآیند اندازهگیری دارای یک کاشی تثبیت کننده مربوطه (به رنگ آبی: X پررنگ و Z کمرنگ) است. عملگرهای منطقی ZL (مشکی) و XL (سبز) این آرایه را میپیمایند، تا در کیوبیت داده پایین سمت چپ، به هم برسند. یکی از چهار ربع، که با خطوط قرمز مشخص شده است، در سمت راست بالا یک کد زیر مجموعه فاصله-3 را نمایش میدهد که در مقایسه با فاصله-5 تجزیه و تحلیل میشود.
برای شناسایی خطاها، به طور متناوب از (d2 – 1) کیوبیت اندازه (که در سراسر شبکه پخش شدهاند) و اندازهگیری پاریتههای X و Z آنها در خوشههای همسایهی کیوبیتهای داده، استفاده میشود. همانگونه که در شکل 2 نشان داده شده است هر کیوبیت اندازه با کیوبیتهای دادهی مجاور تعامل میکند تا پاریتهی مشترک آنها را به حالت کیوبیت اندازه اختصاص دهد. سپس این تخصیص پاریته اندازهگیری میشود. هر تثبیت کننده (stabilizer)، که به عنوان اندازهگیریکنندهی پاریته نیز شناخته میشود، دارای خاصیت جابجاپذیری بین مشاهدهپذیرهای منطقی کیوبیت کدبندی شده با تثبیتکنندههای دیگر است. بنابراین، شناسایی خطاها با مشاهده هرگونه تغییر غیرمنتظره در اندازهگیریهای پاریته بدون تاثیر بر وضعیت منطقی کیوبیت امکانپذیر است.
با استفاده از نتایج اندازهگیری قبلی تثبیتکنندهها، یک کدگشا (decoder) آرایشهای احتمالی خطای فیزیکی موجود در دستگاه را استنباط میکند. پس از آن، میتوان تأثیر این نادرستیهای استنباطشده را بر روی کیوبیت منطقی ارزیابی کرد و در نتیجه وضعیت منطقی آن را حفظ کرد. یکی از راههای اجرای دروازههای منطقی کد سطحی، حفظ حافظه منطقی و انجام مجموعههای مختلف اندازهگیری بر روی مرز کد است. مشکل فنی بسیار مهم در هنگام کار با کد سطح، حفاظت از حافظه منطقی است.
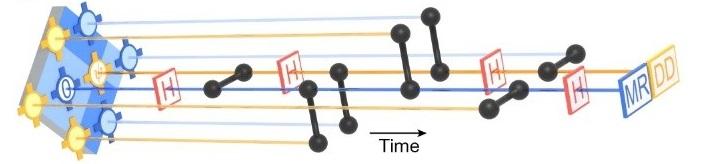
شکل ۲: نمایی از اندازهگیری یک تثبیتکننده
شکل ۲، نمایی از اندازهگیری یک تثبیتکننده، با تاکید بر یک کیوبیت داده تکی با برچسب “y” و یک کیوبیت اندازهگیری با برچسب “0” به تصویر کشیده شده است. نمای پرسپکتیو گذر زمان را از چپ به راست نشان می دهد. چهار دروازهی CZ (که به رنگ سیاه نشان داده شدهاند) بین هر کیوبیت و چهار همسایه نزدیک آن، با شامل کردن گیت هادامارد (H) در بین آنها، اجرا میشود. در نهایت، کیوبیت اندازه، اندازهگیری میشود و به بازنشانی میشود (MR). کیوبیتهای داده در طول دوره انتظار قبل از اندازهگیری و بازنشانی، تحت جداسازی دینامیکی (DD) قرار میگیرند. تمام تثبیتکنندهها به طور همزمان به این روش اندازهگیری میشوند. کل زمان یک چرخه 921 نانوثانیه است که شامل گیتهای تک کیوبیتی 25 نانوثانیه، گیتهای دو کیوبیتی 34 نانوثانیه، فرآیند اندازهگیری 500 نانوثانیه و فرآیند بازنشانی 160 نانوثانیه است. اکثر زمان در طول چرخه توسط فرآیندهای بازخوانی و بازنشانی اشغال میشود و ولگردی (idler) کیوبیت دادههای همزمان را به عنوان علت اصلی خطا در حالت غیرفعال قرار میدهد.
در Google Quantum AI مقیاس شدن کیوبیتها به مقدار خطای مورد نیاز وابسته است. تصحیح خطا با کد سطحی محاسبه و اعمال میشود. در این روش کیوبیتهای ابررسانا مورد استفاده قرار گرفتهاند. کیوبیتهای داده توسط کیوبیتهای اندازهگیری احاطه شدهاند. دو نوع خطای احتمالی میتواند رخ دهد، چرخش بیت (bit flip) یا چرخش فاز (phase flip). کاهش تعداد کیوبیتهای دارای عمر کوتاه، بالا بردن سرعت و دفعات انجام اندازهگیریها، و همچنین بازنشانی حالت کوانتومی نشت یافتهی ناخواسته از جملهی اقدامات و پروتکلهای به کار رفته در این دستاورد هستند. نقش هر یک از پارامترها به این صورت هستند:
دقت در اندازهگیری: تصحیح خطای موفق با تکرار زیاد اندازهگیریها، و بدست آوردن نتایج در درون بازهی خطای مورد قبول محقق میشود. به این حالت بازیابی نتایج میگوییم. باید در نظر داشت که مقدار خطای عملیات اندازهگیری نباید بیشتر از خطاهای احتمالیِ ممکن باشد. این به این معنی است که ابزارها و تکنیکهای اندازهگیری، دقیقتر از خطای کیوبیتها باشند تا بتوانند محل وقوع خطا را شناسایی کنند.
سرعت اندازهگیری: اگر مدت زمان لازم برای اندازهگیری بیشتر از زمان وادوسی کیوبیتها باشد، عملا نمیتواند دادهی موثقی را ایجاد کند. از این رو خطای وادوسی باید خیلی بیشتر از سرعت عملیات اندازهگیری باشد. از سوی دیگر زمانی که اندازهگیری در یک آرایه انجام میشود، زمان وادوسی کل آرایه باید لحاظ شود. در این بین زمان لازم برای بازنشانی حالتهای نشتی نیز باید لحاظ شوند.
افزایش طول عمر کیوبیتها: یکی از نوآوریهای انجام شده توسط این گروه، واجفتشدگی پویا (dynamic decoupling) است که یک فرآیند مؤثر برای اندازهگیری و جداسازی کیوبیتهای خطادار است. در این روش کیوبیتهای خطادار جدا نگهداشته میشوند تا نتوانند به عنوان یک عامل تخریبگر عمل کرده و با همشنوی (crosstalk) سایر کیوبیتهای آرایه را نیز دچار وادوسی یا تغییر حالت کنند. برای نگهداشتن همدوسی و همشنوی با کیوبیتهای اندازهگیریشدهی همسایه، کیوبیتها مرتباً پالس زده میشوند. پروتکل طراحی شده، محدودیتی را برای همشنوی بین کیوبیتها ایجاد میکند تا از مقدار معینی فراتر نروند.
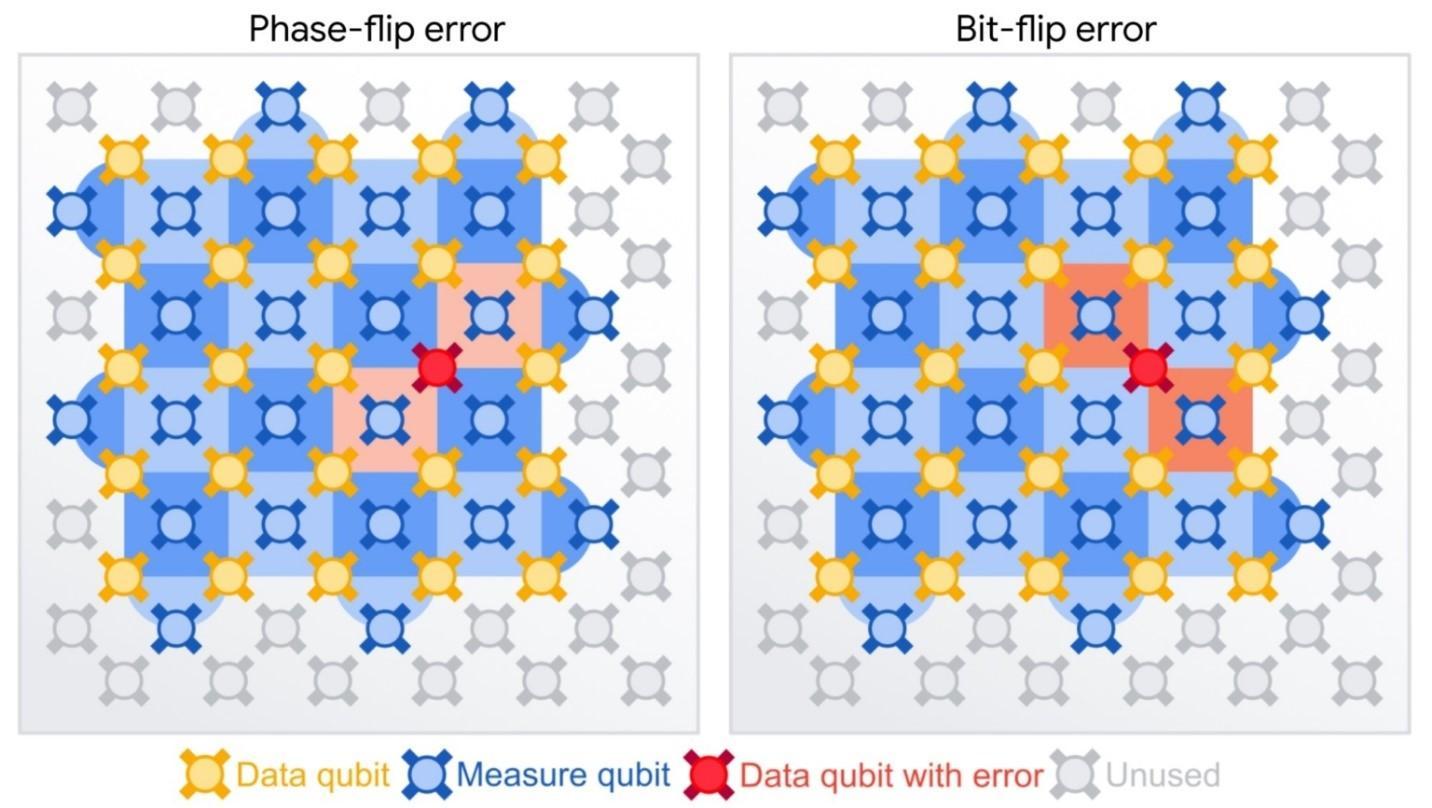
تفسیر و تحلیل دادهها: یکی از مشکلات اصلی در تقسیر و تحلیل دادهها تشخیص خطاهای موجود بدون آگاهی کامل از شرایط سامانه است. یک راه حل این است که از افزار(هایی) استفاده شود که نسبت به عملکرد آن(ها) دانش کامل و کافی وجود دارد. اگر در عمل چنین کدگشاهایی وجود داشته باشند میتوانند خطاها را شناسایی کنند.
با پیاده کردن این روشها و پروتکلها میتوان در عین افزایش تعداد کیوبیتها، خطای تولید را کاهش داد. به طوری که محققین Google Quantum AI به نرخ خطای ۱ در یک میلیون رسیدهاند که در آن نیز بر روی فقط چرخش بیت یا چرخش فاز تمرکز شده است.