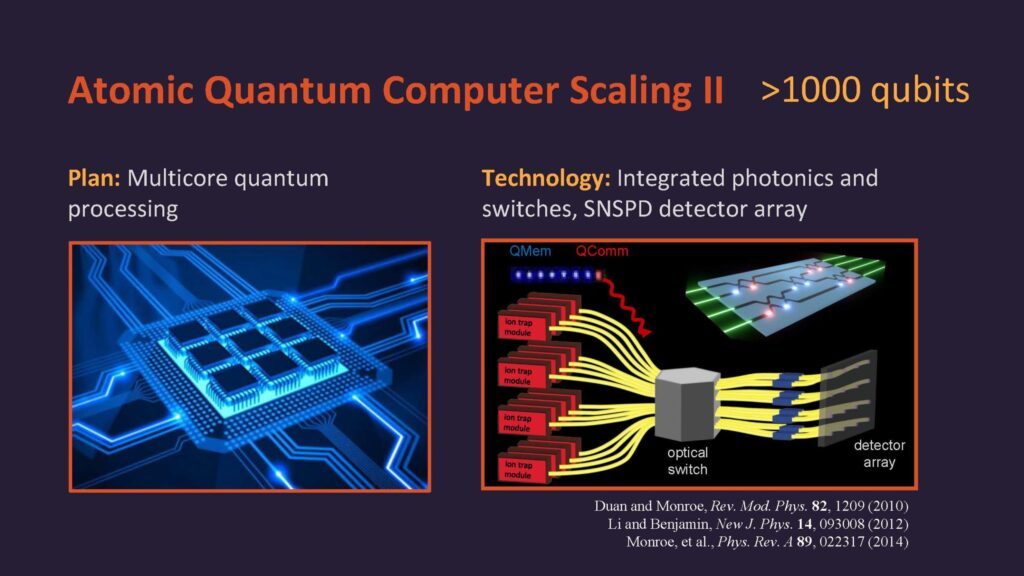
رایانههای کلاسیک در مقایسه با رایانههای کوانتومی
رایانهها یا کامپیوترهای کلاسیکی، بیتهای 0 و 1 را دستکاری میکنند تا اطلاعات را به عنوان دادههای باینری ذخیره کنند، در حالی که رایانههای کوانتومی از احتمال وضعیت یک شی قبل از اندازهگیری استفاده میکنند. بنابراین، این پتانسیل را به آنها میدهد تا دادههای بیشتری را در مقایسه با رایانههای کلاسیک پردازش کنند. بر خلاف رایانههای کلاسیک که از بیت باینری استفاده میکنند، رایانههای کوانتومی از کیوبیتهایی استفاده میکنند که توسط حالت کوانتومی تولید میشوند تا عملیات را انجام دهند. درهمتنیدگی، همبستگی قوی بین ذرات کوانتومی است. این پدیدهها به رایانهی کوانتومی کمک میکند تا با 0، 1 و برهم نهی 0 و 1 کار کند تا محاسبات پیچیده را بتوانند انجام دهند؛ این در حالی است که سیستمهای کلاسیک مدرن نمیتوانند انجام دهند یا برای رسیدن به نتیجه مطلوب زمان قابل توجهی را میطلبند.
یادگیری ماشین کوانتومی یکی از این کاربردها است. در ادامه الگوریتمهای یادگیری ماشین کوانتومی و تکنیک استفاده شده برای ارتقاء این الگوریتمها معرفی شدهاند.
الگوریتمهای کوانتومی برای یادگیری ماشین
در زمینه یادگیری ماشین، ما الگوریتمهایی را توسعه میدهیم که میتوانند از نمونههای دادهشده (ورودیها و خروجیهای دلخواه) یاد بگیرند، به دنبال آن انتظار داریم الگوریتمها مقادیر ورودیهای ناشناخته آینده را پیشبینی کنند.
از سوی دیگر، جدول زیر خلاصه ای از نحوه دستیابی الگوریتم یادگیری ماشین کوانتومی به سرعت در مقایسه با یک کامپیوتر کلاسیک را ارائه میدهد.
خوشهبندی نزدیکترین همسایه و خوشه بندی k-means
الگوریتم خوشهبندی نزدیکترین همسایه یک الگوریتم استاندارد در یادگیری ماشین است. الگوریتم K-نزدیکترین همسایه (KNN) در حین ارزیابی یک آیتم داده جدید که باید بر اساس شباهت و نحوه خوشهبندی همسایههای آن طبقهبندی شود، تمام دادههای قبلی را در نظر میگیرد. هر چه یک بردار به بردار دیگر نزدیکتر باشد، شباهت آنها بیشتر است. روشهای استاندارد برای ارزیابی نزدیکی یا فاصله عبارتند از حاصل ضرب درونی، فاصله همینگ یا اقلیدسی.
ایمور و همکاران از تکنیک همپوشانی یا وفاداری |⟨a|b⟩| برای دو حالت کوانتومی ⟨a⟩ و ⟨b⟩ به منظور اندازهگیری شباهت بین بردارها استفاده میکنند. همپوشانی از طریق یک برنامه فرعی به نام تست جابجایی به دست میآید. بر اساس روش ایمور، لوید وهمکاران یک الگوریتم کوانتومی با زمان اجرای O(log MN) پیشنهاد کردهاند.
در ادامه روند بهبود الگوریتم یادگیری ماشین نزدیکترین همسایه برمن و همکاران الگوریتمهایی برای اندازهگیری فاصله بین بردارهای ویژگیها ارائه کردهاند. این رویکرد که مبتنی بر تست جابجایی است، روشهایی را برای محاسبه فاصله اقلیدسی هم به طور مستقیم و هم با استفاده از حاصلضرب داخلی ارائه میکند. این روش با تقویت دامنه و جستجوی گروور همراه است. با این حال، نمایش اطلاعات کلاسیک از طریق کیوبیتها متفاوت است. در بدترین حالت، الگوریتم در مقایسه با الگوریتمهای مونت کارلو منجر به کاهش چند جملهای میشود.
ماشین بردار پشتیبان (SVM)
SVM ها الگوریتمهای یادگیری ماشین نظارت شده هستند. آنها عمدتاً برای تجزیه و تحلیل خوشهبندی و همچنین برای رگرسیون استفاده میشوند. این الگوریتم از یک نمونه آزمایشی برای آموزش مدل و تخصیص هر مقدار به یکی از کلاسهای موجود استفاده میکند. وظیفه الگوریتم SVM در چنین مسائلی یافتن یک ابر صفحه بهینه بنحوی است که مناطق دو کلاسه را به وضوح جدا میکند و به عنوان یک مرز تصمیم برای ورودیهای آینده عمل میکند.
در اوایل دهه 2000، ویبی و همکاران اولین نسخه SVM کوانتومی که از نوعی جستجوی گروور استفاده میکرد را پیشنهاد کردند. اخیراً روشهای قدرتمندتری که میتوانند دادههای ورودی را از منابعی مانند qRAM که به دادههای کلاسیک دسترسی دارد، یا یک زیربرنامه کوانتومی که حالتهای کوانتومی را آماده میکند توسعه یافته اند. به طور خاص، تخمین فاز کوانتومی برای ایجاد ابرصفحه بهینه و آزمایش بردار ورودی استفاده میشود، که در اصل به زمان log N نیاز دارد. N بعد ماتریسی است که برای تولید نسخه کوانتومی بردار ابرصفحه مورد نیاز است. روشهای شرح داده شده در [8-10] تجزیه و تحلیل دادهها را با استفاده از الگوریتم HHL که یک الگوریتم کوانتومی قدرتمند برای حل دستگاه معادلات خطی است انجام می دهند. الگوریتم HHL توانسته است سرعت حل دستگاه معادلات را بصورت نمایی کاهش دهد. این کاهش سرعت منجر به بهبود الگوریتم های SVM شده است.
شبکه های عصبی کوانتومی (QNN) و یادگیری عمیق
QNN ها شبکههای عصبی محاسباتی هستند که بر روی اصولی که توسط مکانیک کوانتومی اداره میشود کار میکنند. شبکههای عصبی مصنوعی به طور خاص به دلیل کمک آنها در تشخیص الگو و کاربرد در کلان دادهها موردبررسی قرار میگیرند. محققان بر این باورند که استفاده از مفاهیمی مانند درهمتنیدگی، موازی سازی و تداخل ممکن است به بهبود الگوریتمهای شبکه عصبی کمک کند. اخیرا از مفهوم جایگزینی بیت باینری کلاسیک با یک کیوبیت و در نتیجه ایجاد یک سلول عصبی استفاده میکنند. این کیوبیت در برهمنهی از حالتهای فعال و غیرفعال قرار دارد.
در ادامه استفاده از آنیلینگ کوانتومی برای توسعه شبکههای عصبی معرفی شدند. آنیلینگ کوانتومی به راحتی مقیاسپذیر و به صورت تجاری در دسترس است. درنتیجه برای ساخت شبکههای یادگیری کوانتومی عمیق مناسب هستند. یک شبکه یادگیری عمیق که ماشین بولتزمن است، سادهترین شبکه برای تقریب است. خروجی ماشین کوانتومی بولتزمن دادههای کوانتومی بر حسب کیوبیت است. شولد و همکاران در بررسی خود به این نتیجه رسیدهاند که هیچ پیشنهادی وجود ندارد که بتواند از قدرت کامل رایانههای کوانتومی استفاده کند. این به دو دلیل است.اولا استفاده از یک عملگر واحد مانند جمع در فضای هیلبرت (یک فضای حاصل ضرب درونی واقعی یا پیچیده که ویژگیهای خاصی را برآورده میکند) یک حالت نامعتبر ایجاد میکند. ثانیا شبکههای عصبی کلاسیک دارای دینامیک غیرخطی هستند، در حالیکه QNN دارای دینامیک خطی هستند. همه این موارد منجر به این میشود که ما نتوانیم از قدرت رایانههای کوانتومی به صورت تمام و کمال در محاسبات شبکههای عمیق استفاده کنیم.